

AI Battlecards: Why They Are Generic and How to Build Field-Ready Ones
No time to lose? Summarize with AI
ChatGPT
Claude

You asked AI to build a battlecard before a tough pricing call. It gave you clean formatting and advice like "pivot to total cost of ownership."
You closed it and went back to your CRM notes anyway.
Most AI battlecards fail not because AI cannot write, but because they are reading the wrong data.
This blog explains why that happens and what a genuinely deal-grounded battlecard looks like instead.
TL;DR
Most AI battlecards fail because they read web data and static knowledge bases, not your actual closed deals.
A deal-grounded battlecard cites named accounts, word-for-word talk tracks, and win patterns traceable to specific deals.
The right tool generates a fully cited, field-ready battlecard from one natural-language prompt in under 60 seconds.
Why AI Battlecards Fail Reps Before a Call
Most AI battlecard tools pull content from three sources, none of which contain your actual deal intelligence.
Your prompt - Output quality is capped by how well you describe the situation in text.
Generic web data - Public competitor information, your prospect's own vendor has already addressed.
A static knowledge base - A document someone on enablement wrote months ago from a handful of deals they remembered.
None of these sources knows what happened on your last 40 pricing calls. The question is whether your AI battlecard tool can actually reach the intelligence that does.
Here is what that looks like in practice.
Generic Battlecard vs. Deal-Grounded Battlecard
A generic AI battlecard gives you this for a pricing objection:
"Acknowledge the concern. Pivot to total cost of ownership. Emphasize long-term ROI and hidden costs of cheaper alternatives."
Every rep already knows this. It changes nothing in a live call.
A deal-grounded AI battlecard gives you something your rep can actually use:
Named account evidence. Not "a customer saw 314% ROI." The actual account name, the actual outcome, and the actual context you can reference live.
Word-for-word talk tracks. The exact language your best reps used when they won this specific pricing argument, not paraphrased advice.
Win and loss patterns. Which deal sizes, buyer types, and competitive scenarios favor you on pricing, and which do not, so a rep knows when to fight and when to qualify out.
Traceability. The named deal the battlecard was built from, so every claim can be verified before it is used on a call.
The difference is not cosmetic. Here is what a deal-grounded battlecard actually looks like when generated from your own closed deals.
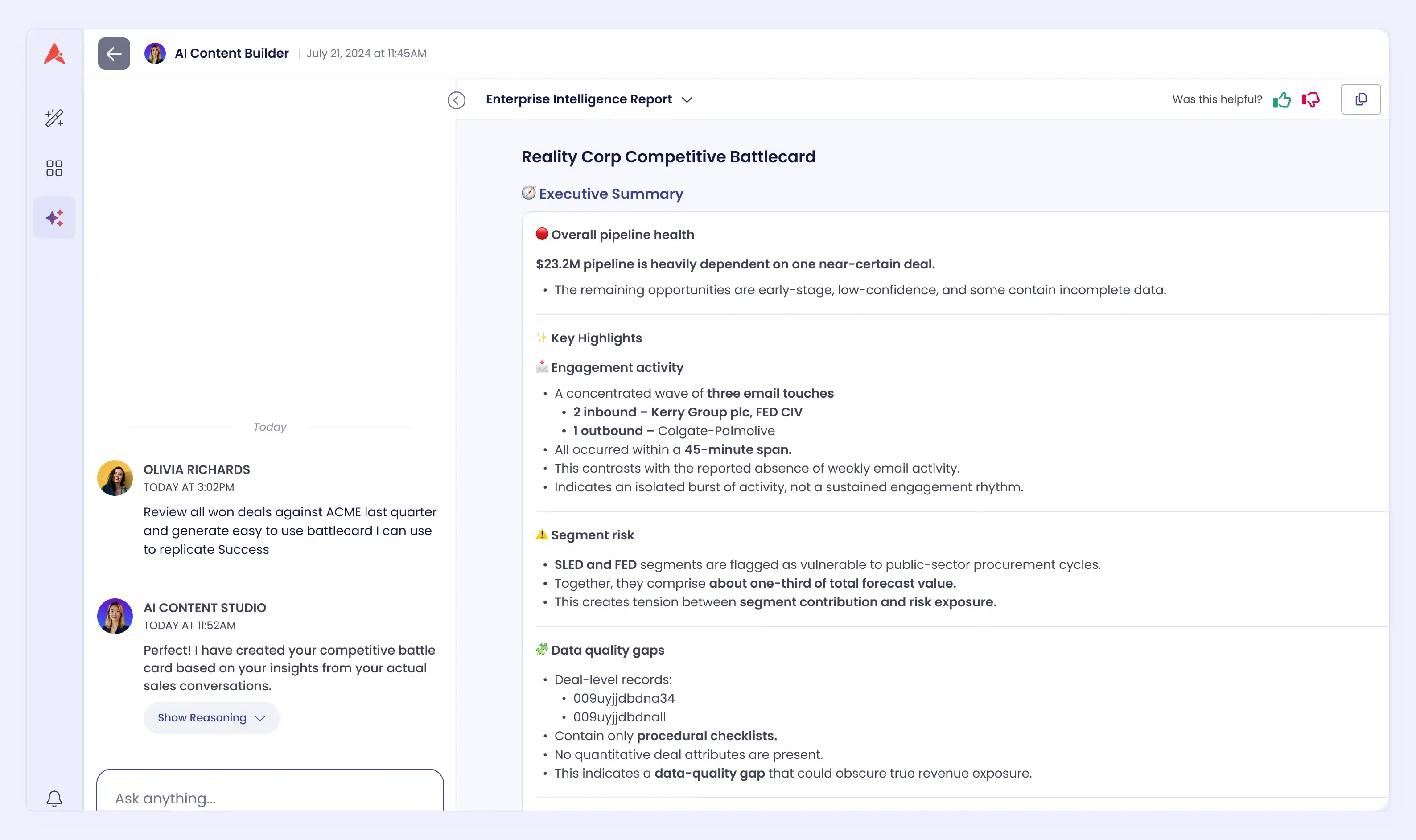
The Fabrication Problem Most Reps Do Not Think About
When you see a statistic in a battlecard, the first question should be: where did this come from?
If the answer is "the AI generated it," that number is worthless in a live call. You cannot cite a hallucinated figure to a skeptical CFO and expect to win the deal.
The right standard is clear:
If the evidence is not in your deal data, the section does not get written.
An empty section is more useful than a confident-sounding claim with no source.
Traceability should be visible inside the output itself, not buried in a settings disclaimer.
A rep should see exactly which deals informed each claim and verify them before the call. That is the only thing that makes AI-generated content trustworthy enough to use in front of a prospect.
Why Pre-Filtering Your Data Is Not the Same as Intelligence
Some tools solve the generic problem by asking you to configure the context before generating anything.
The typical workflow looks like this:
Choose a date range and deal stage
Select a team or folder
Write a keyword-dense prompt using language likely to appear in transcripts
Hope the output structure matches what you actually need
This produces better output than a web-search-based tool. But it puts the intelligence burden entirely on you. A rep who does not know which filters to apply gets mediocre output regardless of how good the underlying data is.
A more durable approach works differently. It assembles context continuously across every signal your revenue organization generates:
Calls, CRM updates, and emails
Deal outcomes and forecast changes
Buyer behavior and engagement patterns
It captures not just what happened in a deal but why it happened and which patterns repeat. When an AI content builder draws from that kind of live context layer, your entire prompt can be one sentence:
"Generate an objection-handling battlecard for pricing. Find deals where prospects said we were too expensive versus a lightweight alternative. Extract the talk tracks and ROI justifications that won."
No filters. No template selection. The system reads your deal history and builds from evidence.
The Six Sections That Make an AI Battlecard Field-Ready
A battlecard built for live use has to be scannable in under 30 seconds. Reps do not read before a call. They scan, find the right response, and go.
A field-ready AI battlecard contains six sections:
1. Quick Reference Card: A competitive positioning table across pricing model, implementation cost, feature depth, support quality, and security. Every row carries an evidence-based differentiator, not a marketing claim.
2. Objection Responses with Account Evidence: Three to five common objections with word-for-word responses tied to real customer outcomes. Not "cite ROI." The actual customer name and the actual number a rep can drop into a conversation.
3. Win and Loss Patterns: A breakdown of when you win and lose on pricing by deal size, buyer type, and competitive scenario. This is the section that tells a rep whether to fight or qualify out before getting on the call.
4. Traceability: The named deal the battlecard was built from. This closes the "did the AI make this up" question permanently, with specific accounts a rep can verify.
5. Risk Assessment: The breakdown points. What stalls or derails a deal even after a strong pricing response. Green signals for a winnable conversation, red flags for structural deal risk.
6. Domain Intelligence: How to think, not just what to say. The competitive and cognitive strategy behind the talk tracks allows a rep to adapt in real time when a conversation goes off-script.
A battlecard containing all six sections is not a draft or a starting point. It is a finished tool that a rep opens five minutes before a call. The intelligence behind each section comes from real call summaries, buyer scores, and competitive signals pulled from your actual deal history.
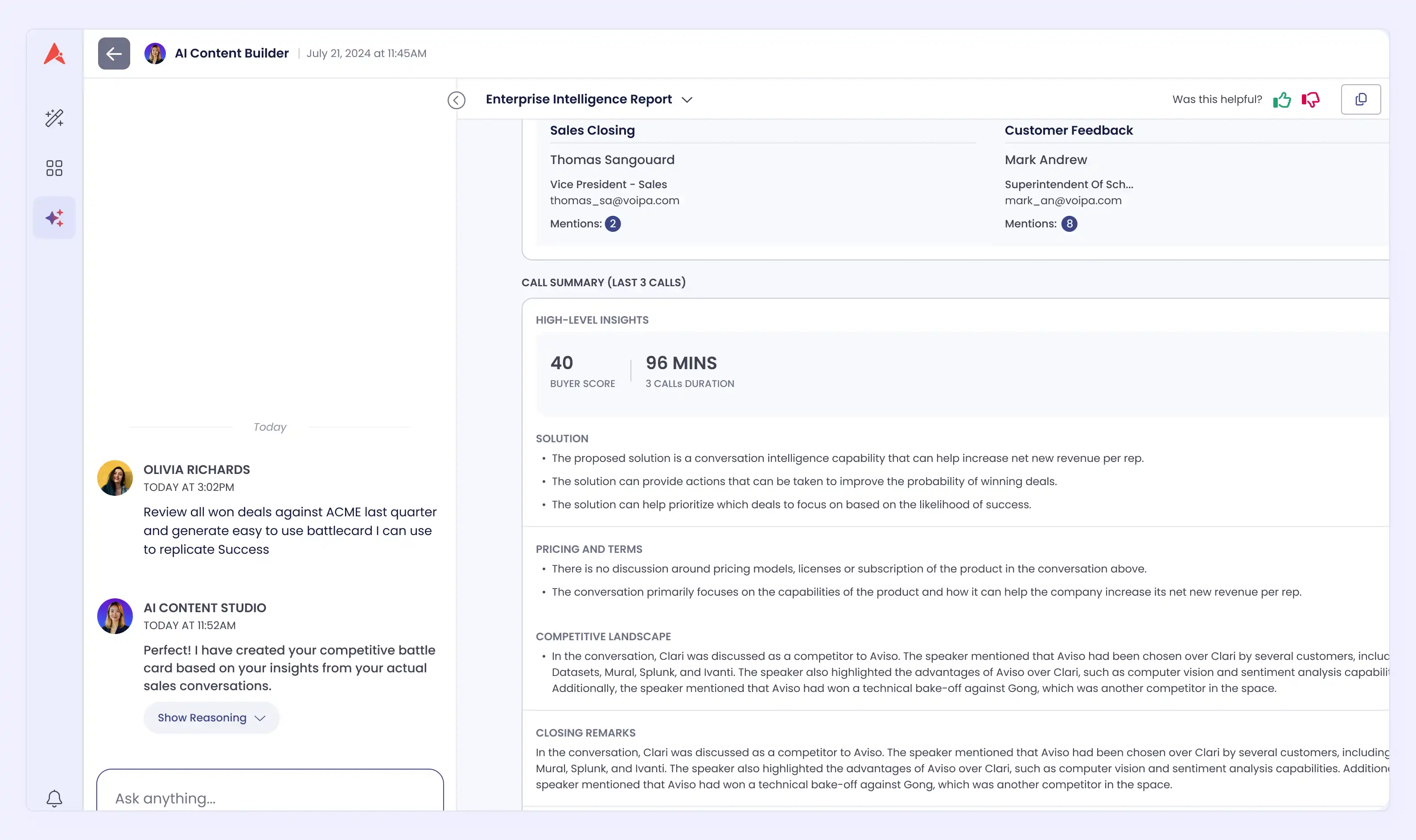
The 60-Second Standard for AI Battlecard Tools
A well-designed AI battlecard tool should produce a fully cited, deal-grounded, field-ready asset from a single natural-language prompt in under 60 seconds.
If generating a useful battlecard requires any of the following, the tool is shifting manual work rather than eliminating it:
Filter setup before you can prompt
Template selection or drop-down configuration
Post-generation editing before the asset is usable
Copying output into another tool to make it look professional
The intelligence to win pricing conversations already exists in your organization. It lives in your won and lost deal history. The reps who won this argument last quarter used specific language, cited specific customers, and followed a specific approach that worked. That intelligence should be available to every rep before their next pricing call, not locked in recordings nobody has time to review.
Fix what the AI is reading, and the output fixes itself.
Check out how AEs are building battlecards with AI the right way:
How to Evaluate Any AI Battlecard Tool
The right tool depends on what it is reading and how honestly it handles gaps. Before committing to any AI battlecard tool, run it against these five questions:
Where does the content come from? Deal history produces usable output. Web data and static knowledge bases produce generic output.
Can it show you what it read? If the tool cannot identify which deals informed each claim, you cannot trust those claims in a live call.
Does it fabricate or omit? A tool that fills sections with unsourced content is a liability. A tool that omits unsourced sections is honest about your intelligence gaps.
How much setup does it require? If useful output requires significant filter configuration, the tool is scaling your setup overhead, not your enablement.
Is the output immediately usable? A clean PDF you open on a second monitor is a finished tool. A block of text you copy into a slide deck is a starting point.
The gap between a generic AI battlecard and a useful one is not a capability gap. It is a data gap.
Beyond Battlecards: Other Assets Aviso's AI Content Builder Generates
Battlecards are the highest-stakes test for AI-generated content. Aviso's AI Content Builder is the tool behind the battlecard standard described above. The same capability extends across every asset a rep or enablement team needs before, during, and after a deal.
From a single prompt, Aviso's AI Content Builder generates:
Call briefs — Account context, open risks, and suggested talk tracks pulled from your deal history before a discovery or renewal call
Executive summaries — Deal-specific narratives for a champion to take into an internal buying committee, grounded in the outcomes your product has delivered to similar accounts
Objection-handling guides — Structured responses to the objections your reps actually face, with named-account evidence behind each one
Competitive one-pagers — Fast-reference comparison assets for a specific competitor, built from how your reps have actually won and lost those deals
ROI justification docs — Outcome evidence assembled from closed deals in the same segment, ready to hand to a skeptical CFO or procurement team
Customer win summaries — Specific outcomes, quotes, and business metrics from your best accounts, ready to use in case studies or live reference conversations
Outreach scripts — Cold call openers and follow-up sequences built from the language and patterns that actually booked meetings in your pipeline
Win-loss reports — Pattern analysis across closed won and closed lost deals by competitor, deal size, and buyer type, so the next rep going into that scenario knows what they are walking into
The underlying standard is the same across all of them. If the evidence is not in your deal data, the section does not get written.
FAQs
Why are AI-generated battlecards usually generic?
Most tools read web data or static knowledge bases rather than your actual deal history. The output reflects general sales advice, not what has worked in your specific deals against your specific competitors.
What makes an AI battlecard trustworthy enough to use in a live call?
Traceability. Every claim should link to a specific deal or named account. If a tool cannot show you which deals it read, you should not cite its output to a prospect.
Can AI generate a battlecard from my CRM data?
Yes, if the tool connects to a context layer that ingests your CRM data continuously. Tools that require manual uploads or filter setup will only be as current as your last configuration, not your last closed deal.
How long should it take to generate an AI battlecard?
Under 60 seconds from a single natural-language prompt. If it takes longer or requires post-generation editing, the tool is not solving the right problem.
What is the difference between an AI battlecard and a traditional battlecard?
A traditional battlecard is built manually from win/loss reviews and competitive research. It is accurate when written, but it becomes outdated quickly. An AI battlecard built from live deal data reflects current patterns across your actual pipeline and updates as new deals close.
Do AI battlecards replace sales enablement teams?
No. AI scales what enablement teams produce, not what they think. The judgment about which patterns matter and how to position your product still requires human expertise. AI handles extraction and formatting. Enablement handles strategy.
What is a sales battlecard?
A sales battlecard is a one-page reference asset that helps a rep handle a specific competitive situation, objection, or buyer scenario in a live call. Traditional battlecards are built manually from win/loss reviews and competitive research. AI battlecards generate the same asset from a single prompt, ideally grounded in live deal data rather than generic web research.
What should a sales battlecard include?
A field-ready sales battlecard includes six sections: a quick reference comparison table, objection responses tied to named-account evidence, win and loss patterns by deal size and buyer type, traceability to the specific deals the content came from, deal risk assessment with green and red signals, and domain intelligence on how to think through the competitive conversation in real time. A battlecard missing any of these is a starting point, not a finished tool.
What are the best AI battlecard tools in 2026?
AI battlecard tools fall into three categories. First, prompt-only tools that read web data and generic knowledge bases (most ChatGPT wrappers). Second, filter-based tools that ask reps to pre-select date ranges, teams, and keywords before generating (most current competitive intelligence platforms). Third, context-graph tools like Aviso's AI Content Builder that continuously ingest CRM, calls, emails, and deal outcomes so the rep can prompt in one sentence and receive a deal-grounded battlecard in under 60 seconds.
How is Aviso's AI Content Builder different from Klue, Crayon, or Kompyte?
Klue, Crayon, and Kompyte are competitive intelligence platforms that organize battlecards around manually curated competitor cards. Aviso's AI Content Builder generates battlecards on demand from live deal data through Aviso's Context Graph. The wedge is what each tool is reading. Klue and Crayon read what their competitive intelligence analysts have written about competitors. Aviso reads what your reps actually said and what your buyers actually responded to, deal by deal.
Can AI battlecards hallucinate facts in a live sales call?
Yes, unless the tool is built to prevent it. Tools that read generic web data or rely on prompt-only generation routinely produce confident-sounding statistics and customer outcomes that did not happen. The right standard is traceability: every claim in a battlecard should link to the specific deal or named account it came from. If a section cannot be sourced from your deal data, the tool should omit it rather than fabricate. An empty section is more useful than a confident hallucination.
The Bottom Line
The intelligence to win pricing conversations is already in your organization. It lives in your closed deals, your won calls, your lost opportunities. Every pricing objection your best rep has ever handled successfully left a trace in your deal history.
The only question is whether your AI battlecard tool can read it, cite it, and put it in front of a rep before the call, not after the loss.
Aviso's AI Content Builder surfaces that intelligence from a single prompt, grounded in your live deal data through Aviso's Context Graph.
See it build a battlecard from your own deal data. See It in Action





