Why Enterprise Revenue AI Costs Are Out of Control and What Aviso Does Differently

No time to lose? Summarize with AI
ChatGPT
Claude

Your AI vendor's pricing page shows a number. Your finance team sees a different number every month. The gap between those two figures is Tokenmaxxing, and it is quietly compounding inside every revenue AI platform that runs on generic LLM inference.
MIKI, Agentic Chief of Staff by Aviso, was built to close that gap. This is how.
TL;DR
Enterprise AI budgets are growing fast, but invoices are growing faster, driven by agentic workflow token multiplication
The root cause is architecture: generic AI agents re-reason from scratch on every query, compounding token costs at every step
MIKI is optimized at the Context Graph level, not the prompt layer, pre-encoding RevOps intelligence, so it never burns tokens rediscovering what it already knows
MIKI also runs Large Quantitative Models alongside LLM orchestration for quantitative predictions and forecast reasoning that generic agents cannot match
Based on Aviso internal benchmarking data, June 2026: MIKI delivers 300K+ queries per $1,000 vs. approximately 4,400 for frontier model deployments at comparable accuracy
The result is 90 to 95% lower operating cost vs. frontier-model-only deployments, with 90%+ answer correctness maintained
This is not a cost optimization story. It is an architectural story that produces a cost outcome
The Enterprise AI Cost Paradox
Something counterintuitive is happening inside enterprise AI budgets right now.
The cost of intelligence is falling. The cost of deploying that intelligence is rising.
The FinOps Foundation's 2026 State of FinOps report found that 73% of enterprises reported their AI costs exceeded original projections.
Price and invoice are moving in opposite directions. The reason is simple once you see it:
Per-token pricing from frontier model providers has dropped dramatically year over year
But enterprise deployments are not running single queries; they are running agentic workflows
A single agentic workflow may trigger 10 to 20 LLM inference calls to complete one user-initiated task
Multiply that by hundreds of sales reps running queries daily, and the math compounds fast
In 2026, inference accounts for 85% of the enterprise AI budget, driven by agentic loops, autonomous agents reasoning in loops, and always-on AI workflows running around the clock.
The unit cost of intelligence is falling. The volume of inference calls required to deliver that intelligence is rising faster.
What Is Tokenmaxxing?
Tokenmaxxing is the pattern where generic AI agents burn tokens, rediscovering intelligence they should already have encoded.
Every query starts cold. No pre-loaded domain context. No CRM hierarchy. No territory structure. The agent reasons from scratch on every single interaction, triggering a chain of inference calls that compound at enterprise scale.
The Tokenmaxxing loop looks like this:
Cold search with no domain context loaded
CRM logic re-derived from scratch on every call
An incomplete first pass triggers a second search
The LLM self-check loop validates the uncertain answer
Retry on failure burns additional tokens before a final answer arrives
The result is not one expensive query. It is that pattern repeating across hundreds of reps, running dozens of workflows, every single day.
Tokenmaxxing is not a bug in one platform. It is the architectural default across revenue AI tools built for seat-based SaaS and retrofitted for agent workflows after the fact. Lower per-token prices from frontier model providers do not fix it. They mask it until the invoice arrives.
Why Most Revenue AI Platforms Have a Token Problem
The Tokenmaxxing pattern hits revenue AI platforms harder than most categories, and the reason is structural.
Most platforms in this space were not designed for agentic workflows. They were designed for seat-based SaaS, then retrofitted to handle usage-based billing after the fact. That retrofit left a predictable cost failure underneath every query:
No pre-loaded forecast context means the agent starts every question blind
No CRM ontology means territory structures and deal hierarchies are re-derived each time
No deterministic validation means uncertain answers trigger LLM self-check loops
No efficient scoping means over-broad context retrieval inflates token counts on every call
One agentic workflow can trigger 10 to 20 LLM inference calls to complete a single user-initiated task. Multiply that by hundreds of reps running queries daily, and the math compounds fast.
In 2026, inference accounts for approximately 85% of the enterprise AI budget, driven by agentic loops, autonomous agents reasoning in loops, and always-on workflows running around the clock.
The unit cost of intelligence is falling. The volume of inference calls required to deliver that intelligence is rising faster. That gap is where enterprise AI budgets break.
What a Token-Efficient Revenue AI Architecture Actually Looks Like
The question is not whether to use AI for revenue execution. The question is whether the AI you are using burns tokens rediscovering intelligence it should already have encoded.
MIKI is built around the opposite principle: Outcomemaxxing. Fewer tokens, pre-encoded intelligence, complete answers.
The core difference: Context Graph vs. Prompt Layer
Traditional agent architectures optimize at the prompt layer. Better prompts extract better answers from generic LLMs. The token cost of re-reasoning is baked into every query.
MIKI is optimized at the Context Graph level instead. Here is what that means in practice:
Forecast concepts, CRM hierarchies, territory structures, deal relationships, and RevOps ontologies are all pre-encoded into the architecture before any query arrives
When a rep asks "which deals are at risk this quarter," MIKI navigates a pre-built graph that already understands what "at risk" means in your revenue context, without cold-searching or re-deriving CRM logic
MIKI also runs Large Quantitative Models alongside LLM orchestration, enabling quantitative predictions, forecast reasoning, and risk identification that generic LLM agents cannot produce without significantly more token overhead
Structured RevOps ontologies scope queries precisely, eliminating the over-broad context retrieval that inflates generic agent token counts
Deterministic validation catches errors without LLM retry loops, so answers arrive without self-check token overhead
The result is a fundamentally different token consumption profile.
MIKI's production query token breakdown:
Based on Aviso internal benchmarking data, June 2026:
Query Type | Example | Tokens | % of Query Mix |
Simple Lookup | Top 10 deals by ARR | 26K | 45% |
Risk Analysis | Deals at risk this quarter | 30K | 25% |
Multi-Dimensional | Region vs. plan vs. last quarter | 43K | 20% |
Deep AMA | Why is the EMEA team missing quota? | 55K | 10% |
Weighted Average | Full production mix | ~34K | 100% |
For context, generic agent architectures consume 55K to 80K tokens for typical queries at the same complexity level.
Download the full MIKI Benchmarking Report to see the complete architecture trace and token breakdown by pipeline stage.
The Numbers That Matter to Your CFO
All figures below are from Aviso internal benchmarking data, June 2026, reflecting production RevOps workflows across CRM, Forecast, and Interaction data.
Query efficiency vs. the market:
MIKI uses 57% fewer tokens per query than standard MCP agents
MIKI uses 21% fewer tokens per query than leading enterprise search competitors
MIKI delivers 2.3x higher relative query efficiency vs. MCP agents at the same task complexity
Cost per query at enterprise scale:
Model / Architecture | Cost Per Query | Queries per $1,000 |
Claude Opus | ~$0.23 | ~4,400 |
GPT 5.5 | ~$0.22 | ~4,600 |
GPT 5.4 | ~$0.12 | ~8,400 |
Gemini 2.5 Pro | ~$0.07 | ~15,000 |
Gemini 2.5 Flash | ~$0.016 | ~62,000 |
MIKI OSS Architecture | ~$0.003 to $0.007 | 150K to 300K+ |
Annual inference cost for a 1,000-rep organization running 20 queries per day:
Claude Opus deployment: approximately $1.25M per year
Gemini 2.5 Flash deployment: approximately $150K per year
MIKI OSS Architecture: significantly below $150K per year
Operating cost reduction vs. frontier-model-only deployments: 90 to 95%.
Approximately $500K to $1.2M in annual savings for a 100-rep organization running 10 agent triggers per day, based on competitor trigger pricing of $1.70 to $7 per trigger vs. Aviso's $1 to $1.50 across 250,000 annual triggers. (based on Aviso internal benchmarking, June 2026; figures vary by team size).
Why Accuracy Does Not Have to Be the Trade-Off
The instinct when seeing cost numbers this low is to ask what is being sacrificed in accuracy. The answer, based on internal benchmarking data, is nothing.
MIKI's accuracy profile:
90%+ answer correctness consistently across production RevOps workflows covering CRM, Forecast, and Interaction data
Utility comparable to leading enterprise AI assistants, combining structured APIs, SQL, and analytical reasoning
Completeness that exceeds retrieval-first systems, including root causes and recommended actions, not just data retrieval
Completeness in practice:
When a revenue leader asks "which regions will miss quota and what actions should I take," here is what generic retrieval-first systems return vs. MIKI:
Capability | Generic / Retrieval-First | MIKI |
Which regions will miss quota | Yes | Yes |
Gap to plan | No | Yes |
Root causes identified | No | Yes |
Recommended actions | No | Yes |
Generic systems return the fact. MIKI returns the fact, the context behind it, and the action to take. That completeness gap is architectural, produced by Large Quantitative Models and RevOps-native planning that generic LLM agents cannot replicate without burning significantly more tokens.
A revenue leader asked MIKI, GPT 5.4, and Gemini Pro to identify which deals to prioritize this quarter based on live pipeline data. Here is what each system returned:
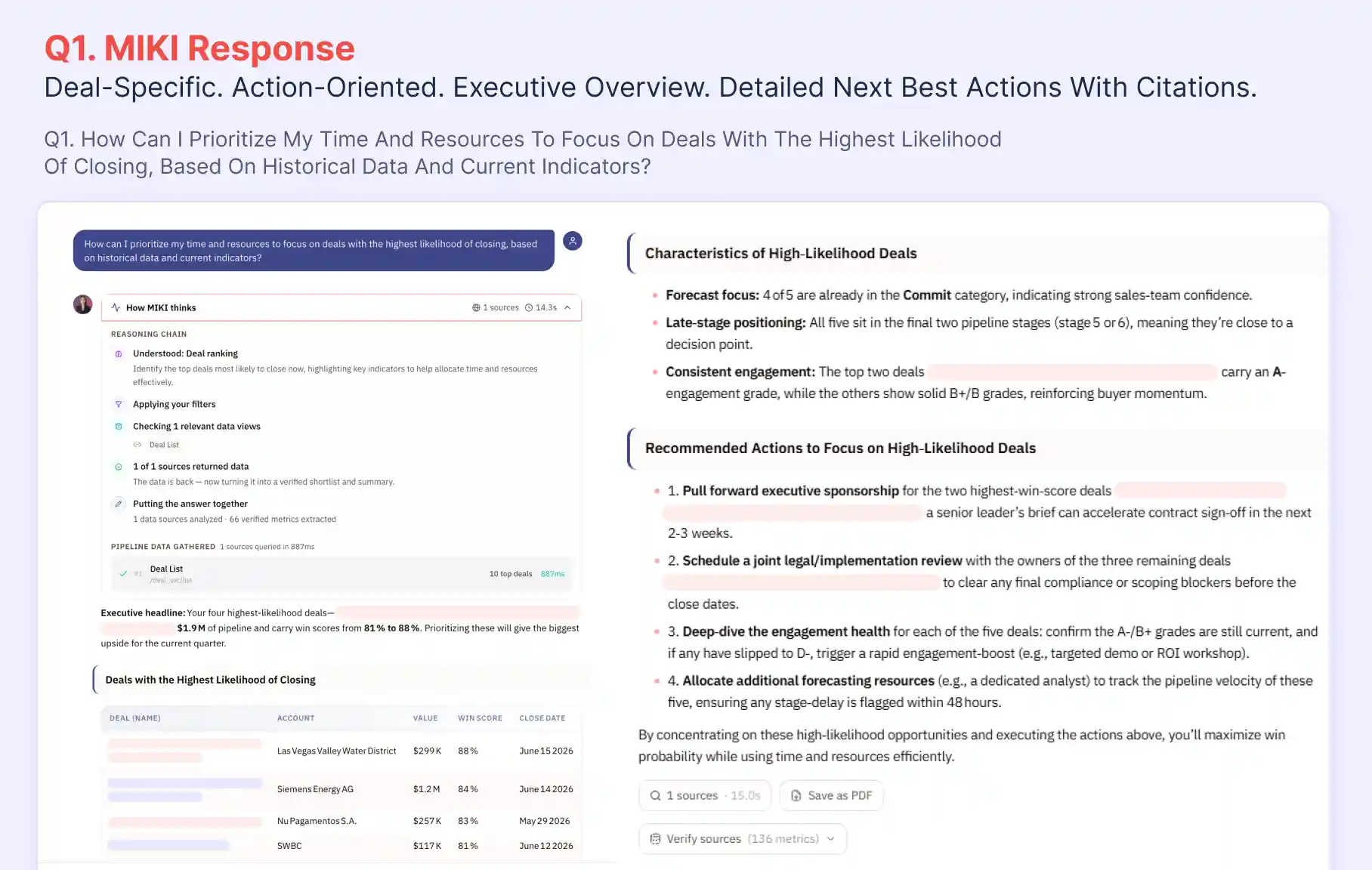


Same dataset. MIKI returned named deals, pipeline values, and four executable actions. GPT 5.4 and Gemini Pro returned frameworks that a rep cannot act on without starting over.
What This Means for How Revenue AI Gets Priced
The token efficiency gap has a direct pricing implication that most buyers miss during vendor evaluation.
Vendors running on high-inference generic architectures face structural pressure.
As reps use the platform more, inference bills grow. That growth has to land somewhere, and it lands in renewal pricing. Here is what the unit economics actually look like across the market:
Leading Competitors | Aviso | |
Seat price | $60+ per seat per month | $60 per seat per month |
Single agent call | $5+ per call or trigger | Free |
Multi-agent call | $100 to $200 per call or trigger | Free |
Enterprise search | Paid, usage-based | Free via Aviso Odyn |
Aviso's revenue intelligence platform is built on a different equation:
Because MIKI's Context Graph minimizes token consumption at the architecture level, the cost of serving more queries does not scale at the same rate
Agent calls are not metered, meaning usage growth does not trigger a surprise invoice
Enterprise search via Aviso Odyn is included at no additional cost, removing a line item that competitors charge separately
Performance-based pricing options tie AI forecast accuracy directly to what you pay, not to how many tokens your reps consume
That is the architectural reason Aviso can offer transparent pricing while platforms running on frontier model APIs face structural pressure to raise prices as usage grows.
The Architecture Comparison Your IT Team Should See
Traditional agent architecture:
Every question starts from scratch. Token overhead compounds at every stage:
Question received with no domain context loaded
Cold search re-derives CRM logic from scratch
Incomplete first pass triggers a second search
LLM self-check loop validates the answer
Retry on failure burns additional tokens before a final answer arrives
MIKI architecture:
Domain intelligence is pre-encoded. Fewer inference steps means lower token cost at every stage:
Question received with RevOps ontology already loaded
Context Graphs navigate CRM, territory, and deal relationships directly
Large Quantitative Models run quantitative predictions and forecast reasoning in parallel
Structured deterministic planner scopes the query precisely
RevOps Skills execute domain-native without re-deriving logic
Deterministic validation catches errors without an LLM retry loop
Answer delivered in approximately 34K weighted average tokens vs. 55K to 80K for generic architectures
The difference is not prompt engineering. It is the intelligence layer beneath the prompt.
Who This Matters Most To
CROs and Revenue Leaders:
You are evaluating AI platforms on outcomes, accuracy, and speed.
The token efficiency story matters because it is why MIKI maintains 90%+ answer correctness without forcing a trade-off between depth and scalability. More queries do not mean worse answers. More usage does not mean a bigger renewal bill.
CFOs and Finance Teams:
For a company with $500M in revenue spending $9 to $19M annually on AI infrastructure, the economics only work if AI reduces costs, increases revenue, or improves decision quality in measurable ways.
MIKI's architecture produces all three outcomes directly:
$500K to $1.2M in annual savings for a 100-rep organization based on agent trigger pricing differential vs. leading competitors
Zero agent call fees and zero enterprise search fees, removing two line items that compound at scale
90%+ answer correctness maintained without accuracy-cost trade-offs that limit other platforms
RevOps and IT Leaders:
In 2026, 98% of FinOps practitioners are responsible for managing AI spend, up from 31% in 2025.
The function that spent a decade governing cloud infrastructure is now managing a cost structure with no established playbook: token-based, consumption-driven, and architecturally volatile.
MIKI gives your team a predictable cost model:
Token consumption is minimized by design, not by usage caps or model downgrades
Architecturally stable costs that do not scale linearly with rep usage
A single benchmarking report that your team can present to finance without a vendor call
FAQs
What is the token problem in enterprise revenue AI?
Generic revenue AI platforms re-reason from scratch on every query, triggering multiple LLM inference calls per workflow. At enterprise scale, that token volume compounds into AI bills that significantly exceed original budget projections.
How does MIKI reduce token consumption without sacrificing accuracy?
MIKI pre-encodes RevOps intelligence into a Context Graph, meaning CRM hierarchies, deal relationships, and territory structures are already loaded when each query arrives. Fewer inference steps means fewer tokens without reducing answer quality.
What are Large Quantitative Models and why do they matter?
Large Quantitative Models are a core component of MIKI's architecture that run quantitative predictions, forecast reasoning, and risk identification alongside LLM orchestration. They enable MIKI to deliver complete, action-oriented revenue answers that generic LLM agents cannot match at the same token cost.
What is MIKI's answer correctness rate in production?
Based on Aviso internal benchmarking data, June 2026, MIKI consistently exceeds 90% answer correctness across production RevOps workflows covering CRM, Forecast, and Interaction data.
How many queries does MIKI deliver per $1,000 vs. frontier models?
Based on Aviso internal benchmarking data, MIKI delivers 150K to 300K+ queries per $1,000 at enterprise scale, compared to approximately 4,400 for Claude Opus and approximately 4,600 for GPT 5.5 at comparable accuracy.
Is MIKI's token efficiency a trade-off against completeness?
No. MIKI's multi-agent composition, Large Quantitative Models, and RevOps-native planning produce more complete answers than retrieval-first systems, including root causes and recommended actions. The efficiency advantage is architectural, not a quality reduction.
What is a Context Graph in revenue AI?
A Context Graph is an architecture layer that pre-encodes domain intelligence including CRM hierarchies, territory structures, deal relationships, and forecast concepts. Rather than re-deriving this context with each query, MIKI navigates it, reducing token overhead and inference cost at every step.
The Bottom Line
The enterprise AI cost crisis is real, well-documented, and accelerating. But it is not an inevitable tax on revenue intelligence. It is a symptom of architectures that were not built for the problem they are being asked to solve.
MIKI was built differently. The token efficiency is not a feature. It is the output of encoding revenue intelligence where it belongs: at the Context Graph level, before the first query ever arrives.





